In this document, we provide all steps and R codes required to estimate the effect of heat waves on the number of years of life lost (YLL) using coarsened exact matching. The implementation is done with the fantastic package MatchIt: do not hesitate to explore its very well-made documentation. We also rely on the cobalt package for checking covariates balance.
Should you have any questions, need help to reproduce the analysis or find coding errors, please do not hesitate to contact us at leo.zabrocki@gmail.com.
Required Packages and Data Loading
To reproduce exactly the coarsened_exact_matching.html document, we first need to have installed:
- the R programming language
- RStudio, an integrated development environment for R, which will allow you to knit the coarsened_exact_matching.Rmd file and interact with the R code chunks
- the R Markdown package
- and the Distill package which provides the template for this document.
Once everything is set up, we load the following packages:
# load required packages
library(knitr) # for creating the R Markdown document
library(here) # for files paths organization
library(tidyverse) # for data manipulation and visualization
library(broom) # for cleaning regression outputs
library(MatchIt) # for matching procedures
library(cobalt) # for assessing covariates balance
library(lmtest) # for modifying regression standard errors
library(sandwich) # for robust and cluster robust standard errors
library(Cairo) # for printing custom police of graphs
library(DT) # for displaying the data as tables
We load our custom ggplot2 theme for graphs:
We finally load the data:
As a reminder, there are 122 days where an heat wave occurred and 1251 days without heat waves.
Coarsened Exact Matching
We implement below a coarsened exact matching procedure where:
- each day with an heat wave is matched to the most similar day without heat wave according to coarsened covariates. This is a 1:1 nearest neighbor matching without replacement.
- We match units according the three lags of the heat wave indicator, the first lag of ozone coarsened into terciles, nitrogen dioxide first lag coarsened into two bins, the relative humidity coarsened into terciles, the month and the year split into periods (“1990-2000” and “2001-2007”).
We explored many different types of coarsening and the values we chose seemed to result in the best sample size-covariates balance trade-off.
Once treated and control units are matched, we assess whether covariates balance has improved.
We finally estimate the treatment effect.
Matching Procedure and Covariates Balance Improvement
We implement below the coarsened exact matching procedure:
# first we split the year variable into two periods
data <- data %>%
mutate(year_binned = as.numeric(as.character(year))) %>%
mutate(year_binned = case_when(year_binned <= 2000 ~ "1990-2000",
year_binned > 2000 ~ "2001-2007"),
year = as.factor(year))
# we set the cut-points for continuous covariates
cutpoints = list(
o3_lag_1 = "q3",
no2_lag_1 = 2,
humidity_relative = "q3"
)
# we implement the matching procedure
matching_coarsened <-
matchit(
heat_wave ~ heat_wave_lag_1 + heat_wave_lag_2 + heat_wave_lag_3 +
o3_lag_1 + no2_lag_1 + humidity_relative +
month + year_binned,
data = data,
method = "cem",
cutpoints = cutpoints,
k2k = TRUE
)
# display results
matching_coarsened
A matchit object
- method: Coarsened exact matching
- number of obs.: 1373 (original), 158 (matched)
- target estimand: ATT
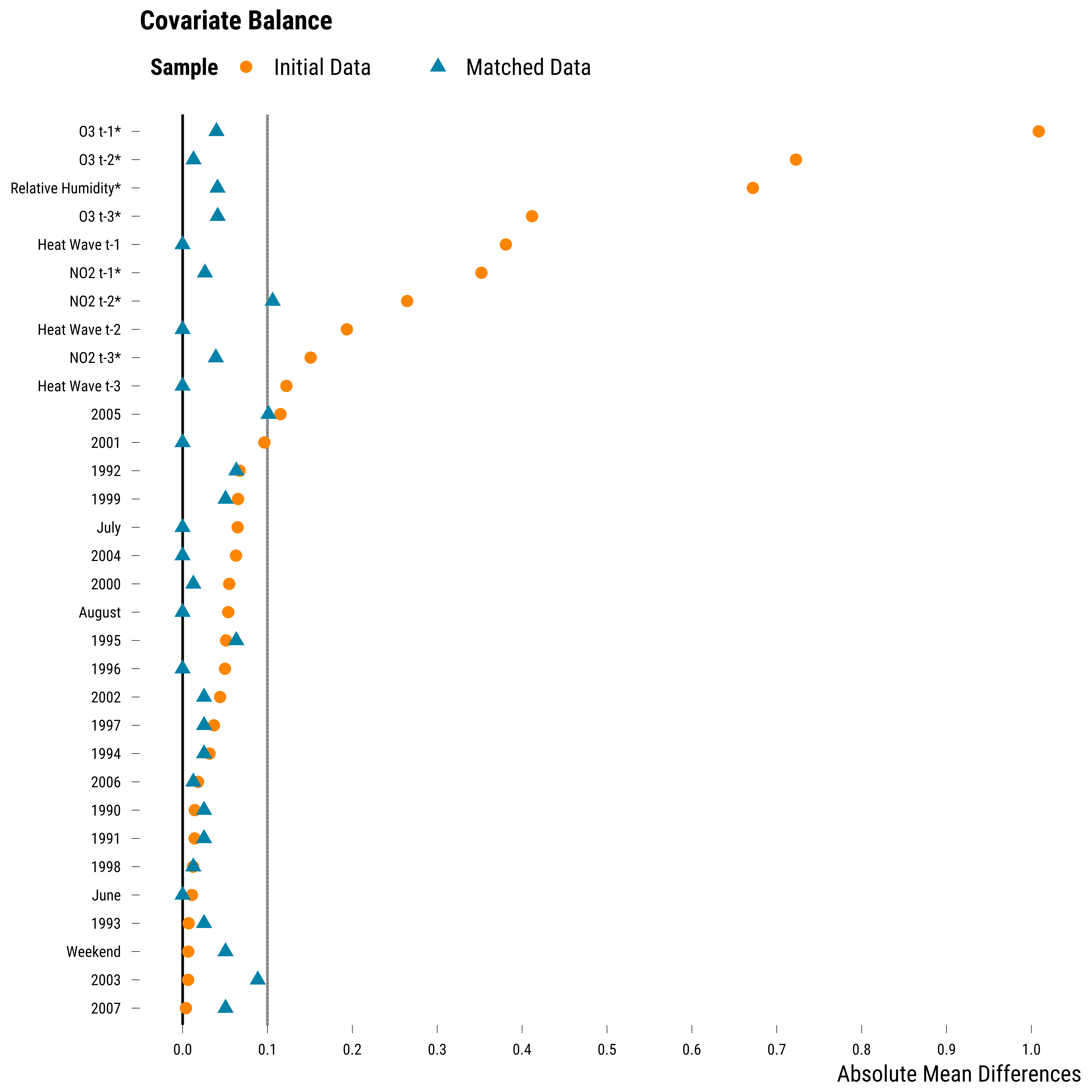
- covariates: heat_wave_lag_1, heat_wave_lag_2, heat_wave_lag_3, o3_lag_1, no2_lag_1, humidity_relative, month, year_binnedThe outputtells us that only 158 units were matched. We then evaluate
the covariates balance using the love.plot() function from
the cobalt package and the absolute mean difference as the summary
statistic. For binary variables, the absolute difference in proportion
is computed. For continuous covariates, denoted with a star, the
absolute standardized mean difference is computed (the difference is
divided by the standard deviation of the variable for treated units
before matching).
Please show me the code!
# first we nicely label covariates
cov_labels <- c(
heat_wave_lag_1 = "Heat Wave t-1",
heat_wave_lag_2 = "Heat Wave t-2",
heat_wave_lag_3 = "Heat Wave t-3",
o3_lag_1 = "O3 t-1",
o3_lag_2 = "O3 t-2",
o3_lag_3 = "O3 t-3",
no2_lag_1 = "NO2 t-1",
no2_lag_2 = "NO2 t-2",
no2_lag_3 = "NO2 t-3",
humidity_relative = "Relative Humidity",
weekend = "Weekend",
month_august = "August",
month_june = "June",
month_july = "July",
year_1990 = "1990",
year_1991 = "1991",
year_1992 = "1992",
year_1993 = "1993",
year_1994 = "1994",
year_1995 = "1995",
year_1996 = "1996",
year_1997 = "1997",
year_1998 = "1998",
year_1999 = "1999",
year_2000 = "2000",
year_2001 = "2001",
year_2002 = "2002",
year_2003 = "2003",
year_2004 = "2004",
year_2005 = "2005",
year_2006 = "2006",
year_2007 = "2007")
# make the love plot
graph_love_plot_cm <- love.plot(
heat_wave ~ heat_wave_lag_1 + heat_wave_lag_2 + heat_wave_lag_3 + o3_lag_1 + o3_lag_2 + o3_lag_3 + no2_lag_1 + no2_lag_2 + no2_lag_3 + humidity_relative + weekend + month + year,
data = data,
estimand = "ATT",
weights = list("Matched Data" = matching_coarsened),
drop.distance = TRUE,
abs = TRUE,
var.order = "unadjusted",
binary = "raw",
s.d.denom = "treated",
thresholds = c(m = .1),
var.names = cov_labels,
sample.names = c("Initial Data", "Matched Data"),
shapes = c("circle", "triangle"),
colors = c(my_orange, my_blue),
stars = "std"
) +
scale_x_continuous(breaks = scales::pretty_breaks(n = 10)) +
xlab("Absolute Mean Differences") +
theme_tufte()
# display the graph
graph_love_plot_cm
Please show me the code!
# save the graph
ggsave(
graph_love_plot_cm,
filename = here::here(
"inputs", "3.outputs",
"2.graphs",
"graph_love_plot_cm.pdf"
),
width = 20,
height = 15,
units = "cm",
device = cairo_pdf
)
On this graph, we see whether covariates balance has increased for most covariates but for some years. We divided the year variable in only two groups to help increase the sample size. If we increase the number of groups, we do not find similar pairs of treated and control units. We display below the evolution of the average of standardized mean differences for continuous covariates:
Please show me the code!
| Sample | Average of Standardized Mean Differences | Std. Deviation |
|---|---|---|
| Initial Data | 0.51 | 0.30 |
| Matched Data | 0.04 | 0.03 |
We also display below the evolution of the difference in proportions for binary covariates:
Please show me the code!
| Sample | Average of Proportion Differences | Std. Deviation |
|---|---|---|
| Initial Data | 0.06 | 0.08 |
| Matched Data | 0.03 | 0.03 |
Overall, the balance has clearly improved after matching for continuous covariates but less so for categorical variables.
We finally save the data on covariates balance in the
3.outputs/1.data/covariates_balance folder.
Analysis of Matched Data
We now move to the analysis of the matched datasets. It is very important to note that the target causal estimand is not anymore the average treatment effect on the treated as not all treated units could be matched to similar control units. We retrieve the matched dataset:
# we retrieve the matched data
data_cm <- match.data(matching_coarsened)
To estimate the treatment effect of heat waves on YLL, we first use a simple regression model where we regress the YLL on the treatment indicator.
# we fit the regression model
model_cm_wo_cov <- lm(yll ~ heat_wave,
data = data_cm,
weights = weights)
# retrieve the estimate and 95% ci
results_cm_wo_cov <- tidy(coeftest(
model_cm_wo_cov,
vcov. = vcovCL,
cluster = ~ subclass
),
conf.int = TRUE) %>%
filter(term == "heat_wave") %>%
dplyr::select(term, estimate, conf.low, conf.high) %>%
mutate_at(vars(estimate:conf.high), ~ round(., 0))
# display results
results_cm_wo_cov %>%
rename(
"Term" = term,
"Estimate" = estimate,
"95% CI Lower Bound" = conf.low,
"95% CI Upper Bound" = conf.high
) %>%
kable(., align = c("l", "c", "c", "c"))
| Term | Estimate | 95% CI Lower Bound | 95% CI Upper Bound |
|---|---|---|---|
| heat_wave | 221 | 71 | 370 |
We find that the estimate for the treatment is equal to +221 years of life lost. The 95% confidence interval is consistent with effects ranging from +71 YLL up to +370 YLL. If we want to increase the precision of our estimate and remove any remaining imbalance in covariates, we can also run a multivariate regression. We adjust below for the same variables used in the propensity score matching procedure and the day of the week:
# we fit the regression model
model_cm_w_cov <-
lm(
yll ~ heat_wave + no2_lag_2 + year,
data = data_cm,
weights = weights
)
# retrieve the estimate and 95% ci
results_cm_w_cov <- tidy(coeftest(model_cm_w_cov,
vcov. = vcovCL,
cluster = ~ subclass),
conf.int = TRUE) %>%
filter(term == "heat_wave") %>%
dplyr::select(term, estimate, conf.low, conf.high) %>%
mutate_at(vars(estimate:conf.high), ~ round(., 0))
# display results
results_cm_w_cov %>%
rename(
"Term" = term,
"Estimate" = estimate,
"95% CI Lower Bound" = conf.low,
"95% CI Upper Bound" = conf.high
) %>%
kable(., align = c("l", "c", "c", "c"))
| Term | Estimate | 95% CI Lower Bound | 95% CI Upper Bound |
|---|---|---|---|
| heat_wave | 308 | 165 | 450 |
We find that the average effect on the treated is equal to +308 years of life lost. The 95% confidence interval is consistent with effects ranging from +165 YLL up to +450 YLL. The width of confidence interval is now equal to 285 YLL, which is a bit smaller than the previous interval of 299 YLL.
We finally save the data on coarsened results in the
3.outputs/1.data/analysis_results folder.
Please show me the code!
bind_rows(
results_cm_wo_cov,
results_cm_w_cov) %>%
mutate(
procedure = c(
"Coarsened Matching without Covariates Adjustment",
"Coarsened Matching with Covariates Adjustment"),
sample_size = rep(sum(matching_coarsened[["weights"]]), 2)
) %>%
saveRDS(
.,
here::here(
"inputs", "3.outputs",
"1.data",
"analysis_results",
"data_analysis_cem.RDS"
)
)