In this document, we took great care providing all steps and R codes required to build the data we use in our analysis at the hourly level.
Should you have any questions, need help to reproduce the analysis or find coding errors, please do not hesitate to contact us at leo.zabrocki@gmail.com and marion.leroutier@hhs.se.
Required Packages
We load the following packages:
# load required packages
library(rmarkdown) # for creating the R Markdown document
library(knitr) # for creating the R Markdown document
library(here) # for files paths organization
library(tidyverse) # for data manipulation and visualization
library(data.table) # for loading heavy data
library(lubridate) # for manipulating date variables
library(missRanger) # for missing values imputation
library(kableExtra) # for table formatting
library(Cairo) # for printing custom police of graphs
We also load our custom ggplot2 theme for graphs:
Maritime Traffic Data
To clean maritime traffic data, we proceed as follows:
- We open the raw data and select the relevant variables.
- We impute missing values for the gross tonnage, which is a measure of a vessel’s volume.
- We classify vessels into three categories (cruise, ferry, and other types of vessels).
- We compute figures to capture maritime traffic intensity which is the hourly total gross tonnage of vessels docking or leaving the port.
Selecting Relevant Observations and Variables
We obtained data on vessel traffic from the Marseille Port authority which supervises two ports: one in Marseille’s city center and the other one in Fos-sur-Mer, which is about 50 kilometers away from Marseille. For each hour, for both the Western (Fos-sur-Mer’s port) and Eastern (Marseille’s port) basins, we know how many ships entered the port, the ships’ characteristics, as well as the exact times of arrival and departure. We received two datasets for the 2008-2012 period (marseille_port_data_2008_2012.xlsx) and the 2013-2018 period (marseille_port_data_2013_2018.xlsx). We open both datasets, located in the 1.data/2.maritime_traffic_data folder and bind them:
# read maritime traffic data
marseille_port_data_2008_2012 <-
data.table::fread(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"1.raw_data",
"1.maritime_traffic_data",
"marseille_port_data_2008_2012.csv"
),
dec = ","
)
marseille_port_data_2013_2018 <-
data.table::fread(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"1.raw_data",
"1.maritime_traffic_data",
"marseille_port_data_2013_2018.csv"
),
dec = ","
)
# bind the two datasets
port_data <-
bind_rows(marseille_port_data_2008_2012,
marseille_port_data_2013_2018)
We rename the variables:
port_data <- port_data %>%
rename(# port call number
port_call_number = "ESC - Numéro d'annonce",
# basin id: west or east
port_basin = "IP - Libellé long",
# vessel's holder name
holder_name = "POR - Nom du porteur",
# vessel's catagory
vessel_category = "POR - Catégorie",
# construction year
construction_year = "POR - Année construction",
# vessel's country flag
country_flag = "POR - Label pavillon",
# vessel's height
vessel_height = "POR - Longueur Ht",
# vessel's width
vessel_max_width = "POR - Largeur Max",
# vessel's maximum hull draft
vessel_hull_draft_max = "POR - Tirant Eau Max Eté",
# vessel's gross tonnage
gross_tonnage = "POR - Jauge Brute",
# vessel's deadweight tonnage
deadweight_tonnage = "POR - Port Lourd",
# vessel's arrival date
entry_date = "ESC - Date d'entrée réelle",
# vessel's port of origin
originating_port = "GEO PROV - Nom localité/port",
# vessel's country of origin
originating_country = "GEO PROV - Nom pays",
# vessel's exit date
exit_date = "ESC - Date de sortie réelle",
# vessel's port of destination
destination_port = "GEO DEST - Nom localité/port",
#vessel's country od destination
destination_country = "GEO DEST - Nom pays"
)
We filter the vessels which docked in or left from the east basin, which is located in Marseille’s city:
port_data <- port_data %>%
# filter vessels docking in east bassin
filter(port_basin == "Bassin Est")
We have data for 41015 port calls. We then select the relevant variables:
port_data <- port_data %>%
# select relevant variables
select(holder_name:destination_country) %>%
# convert continuous variables to numeric
mutate_at(vars(vessel_height:deadweight_tonnage), ~ as.numeric(.))
Since a same vessel could dock in several times, we create a unique id for each vessel call:
port_data <- port_data %>%
# create the unique vessel call id
mutate(vessel_call_id = seq(1:41015))
Before cleaning the data further, it is very important to note that all variables have minor recording issues. For instance, below is a table of summary statistics for the continuous variables:
Please show me the code!
port_data %>%
# select continuous variables
select(vessel_height:deadweight_tonnage) %>%
# transform the data in long format
pivot_longer(
cols = c(vessel_height:deadweight_tonnage),
names_to = "Variable",
values_to = "value"
) %>%
# compute the statistics for each continuous variable
group_by(Variable) %>%
summarise(
"Mean" = round(mean(value, na.rm = TRUE), 1),
"Standard Deviation" = round(sd(value, na.rm = TRUE), 1),
"Minimum" = round(min(value, na.rm = TRUE), 1),
"Maximum" = round(max(value, na.rm = TRUE), 1),
"Number of Missing Values" = sum(is.na(value)),
"Number of Values <= 0" = round(sum(value < 1), 1)
) %>%
# ungroup the data
ungroup() %>%
# reorder the levels of the the variable
mutate(
Variable = fct_relevel(
Variable,
"vessel_height",
"vessel_max_width",
"vessel_hull_draft_max",
"gross_tonnage",
"deadweight_tonnage"
)
) %>%
# sort variable
arrange(Variable) %>%
# correctly label the levels
mutate(
Variable = recode(
Variable,
vessel_height = "Vessel's Height",
vessel_max_width = "Vessel's Width",
vessel_hull_draft_max = "Vessel's Maximum Hull Draft",
gross_tonnage = "Gross Tonnage",
deadweight_tonnage = "Deadweight Tonnage"
)
) %>%
# print the table
kable(., align = c("l", rep("c", 5))) %>%
kable_styling(position = "center")
| Variable | Mean | Standard Deviation | Minimum | Maximum | Number of Missing Values | Number of Values <= 0 |
|---|---|---|---|---|---|---|
| Vessel’s Height | 165.6 | 53.2 | 6.0e+00 | 396.0 | 0 | 0 |
| Vessel’s Width | 25.6 | 6.4 | 1.5e+00 | 77.1 | 0 | 0 |
| Vessel’s Maximum Hull Draft | -3901004.9 | 197473672.1 | -1.0e+10 | 23.0 | 0 | 58 |
| Gross Tonnage | -24596682.7 | 495633297.4 | -1.0e+10 | 228081.0 | 0 | 109 |
| Deadweight Tonnage | -4868188.0 | 220771685.3 | -1.0e+10 | 187625.0 | 0 | 79 |
From this table, we can see that the height and width of vessels seem to be recorded with plausible values while vessels’ hull draft, gross tonnage and deadweight tonnage are not. Indeed, negative or zero values are not possible and should be replaced with missing values. It is however reasuring that there are very few observations with such wrongly recorded values.
After inspecting the data, we think that these recording issues are minor since they concern few observations. We decided to focus on correcting the variables used as proxies for the intensity of maritime traffic as we rely on them for estimating its contribution to background air pollution in Marseille. A first possibility would be to use the daily number of vessels entering and leaving the port, but this variable does not account for differences in vessel size. Yet it should matter for emissions. The gross tonnage of a ship, which measures the ship’s overall internal volume, could be a good proxy for fuel consumption and thus vessel’ emissions during the manoeuvring phases.
In the next section, we show how we clean the gross tonnage variable as well as an alternative measure of vessel size, the deadweight tonnage, that could help us impute missing values for the former variable:
- 182 observations of the gross tonnage, that is to say 0.4 % are not correctly recorded.
- this is also the case for the deadweight tonnage where up to 3.2% of the observations seem to be wrongly recorded. We first replace these observations with missing values and then impute them using a chained random forest algorithm provided by the missRanger package.
Imputing Missing Values
We first carry out a small simulation exercise to show that the
algorithm imputes the missing values well. First, we create a new
dataframe called port_data_test where we drop the
observations for which the gross tonnage and the deadweight tonnage are
wrongly recorded:
Then, we create the dataframe
**port_data_test_na** where we randomly erase
182 of the gross tonnage and deadweight tonnage values.
# sample 182 ids of observations to be erased
ids_na <- sample(seq(1:40833), 182, replace = FALSE)
# erase the gross tonnage and deadweight tonnage values for these randomly chosen observations
port_data_test_na <- port_data_test %>%
mutate(
gross_tonnage = ifelse(id %in% ids_na, NA, gross_tonnage),
deadweight_tonnage = ifelse(id %in% ids_na, NA, deadweight_tonnage)
)
We run the imputation algorithm and create the
port_data_test_imputed dataframe. We impute the gross
tonnage and deadweight tonnage variables using the values observed for
these two variables and the vessels’ height and width as they are
related to the computation of these two figures. We use 50 trees and a
predictive mean matching parameter equal to 3 since, after several
iterations of the imputation process, they lead to credible imputed
values:
# running the imputation algorithm
port_data_test_imputed <- missRanger(
port_data_test_na,
formula = gross_tonnage + deadweight_tonnage ~ gross_tonnage + deadweight_tonnage + vessel_height + vessel_max_width,
pmm.k = 3,
num.trees = 50,
seed = 42
)
Missing value imputation by random forests
Variables to impute: gross_tonnage, deadweight_tonnage
Variables used to impute: gross_tonnage, deadweight_tonnage, vessel_height, vessel_max_width
iter 1: ..
iter 2: ..
iter 3: ..We can now plot the density distribution of the true values of the gross tonnage observations against the imputed values:
Please show me the code!
# true gross tonnage values
true_gross_tonnage <- port_data_test %>%
filter(id %in% ids_na) %>%
select(id, gross_tonnage) %>%
rename("True Gross Tonnage" = gross_tonnage)
# imputed gross tonnage values
imputed_gross_tonnage <- port_data_test_imputed %>%
filter(id %in% ids_na) %>%
select(id, gross_tonnage) %>%
rename("Imputed Gross Tonnage" = gross_tonnage)
# joining the true and imputed values together
gross_tonnage_comparison_df <-
left_join(true_gross_tonnage, imputed_gross_tonnage, by = "id")
# plotting the density distributions
gross_tonnage_comparison_df %>%
gather(., key = "variable", value = "value",-id) %>%
ggplot(., aes(x = value, colour = variable)) +
geom_density(alpha = 0.2) +
scale_color_manual(
name = "Observations:",
labels = c("True Gross Tonnage", "Imputed Gross Tonnage"),
values = c(my_blue, my_orange)
) +
ggtitle("Comparing True and Imputed Gross Tonnage Values") +
scale_y_continuous(labels = scales::comma) +
ylab("Density") +
xlab("Gross Tonnage") +
labs(colour = "Observations:") +
theme_tufte()
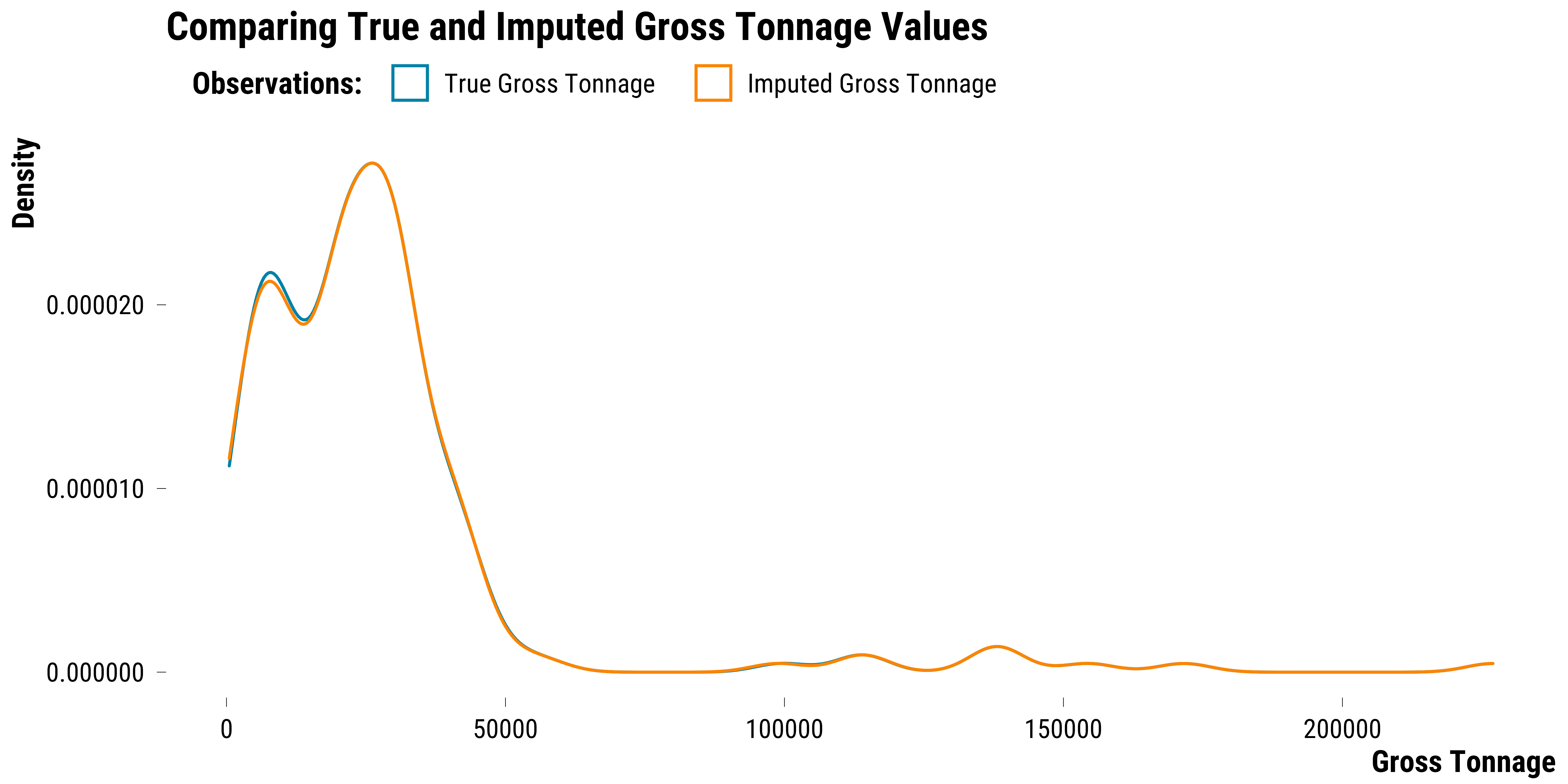
Below is the table with the true values for gross tonnage and the ones imputed by the algorithm and their difference:
Please show me the code!
# joining the true and imputed values together and computing the difference
gross_tonnage_comparison_df <-
left_join(true_gross_tonnage, imputed_gross_tonnage, by = "id") %>%
mutate(Difference = abs(`True Gross Tonnage` - `Imputed Gross Tonnage`)) %>%
rename("Observation Id" = id)
# print the table
rmarkdown::paged_table(gross_tonnage_comparison_df)
The absolute average difference is 156. Given that average gross tonnage value is 2.94014^{4}, this is a relatively small imputation error.
Of course, this is a simple example where the values were erased at random. The imputation algorithm could have more trouble to impute values under different missingness scenarios. We still think it is better to impute our missing observations than dropping them and we should keep in mind that they only represent 0.4 % of the total number of observations.
We now impute the real missing values for the gross tonnage and deadweight tonnage variables:
# replace wrongly recorded gross tonnage and deadweight tonnage observations by missing values
port_data <- port_data %>%
mutate(id = seq(1:41015)) %>%
mutate(
gross_tonnage = ifelse(gross_tonnage < 2, NA, gross_tonnage),
deadweight_tonnage = ifelse(deadweight_tonnage < 2, NA, deadweight_tonnage)
)
# record the index of these variables
ids_na <- port_data %>%
filter(is.na(gross_tonnage)) %>%
select(id) %>%
deframe()
# running the imputation algorithm
port_data <-
missRanger(
port_data,
formula = gross_tonnage + deadweight_tonnage ~ gross_tonnage + deadweight_tonnage + vessel_height + vessel_max_width,
pmm.k = 3,
num.trees = 50,
seed = 42
)
Missing value imputation by random forests
Variables to impute: gross_tonnage, deadweight_tonnage
Variables used to impute: gross_tonnage, deadweight_tonnage, vessel_height, vessel_max_width
iter 1: ..
iter 2: ..
iter 3: ..
iter 4: ..
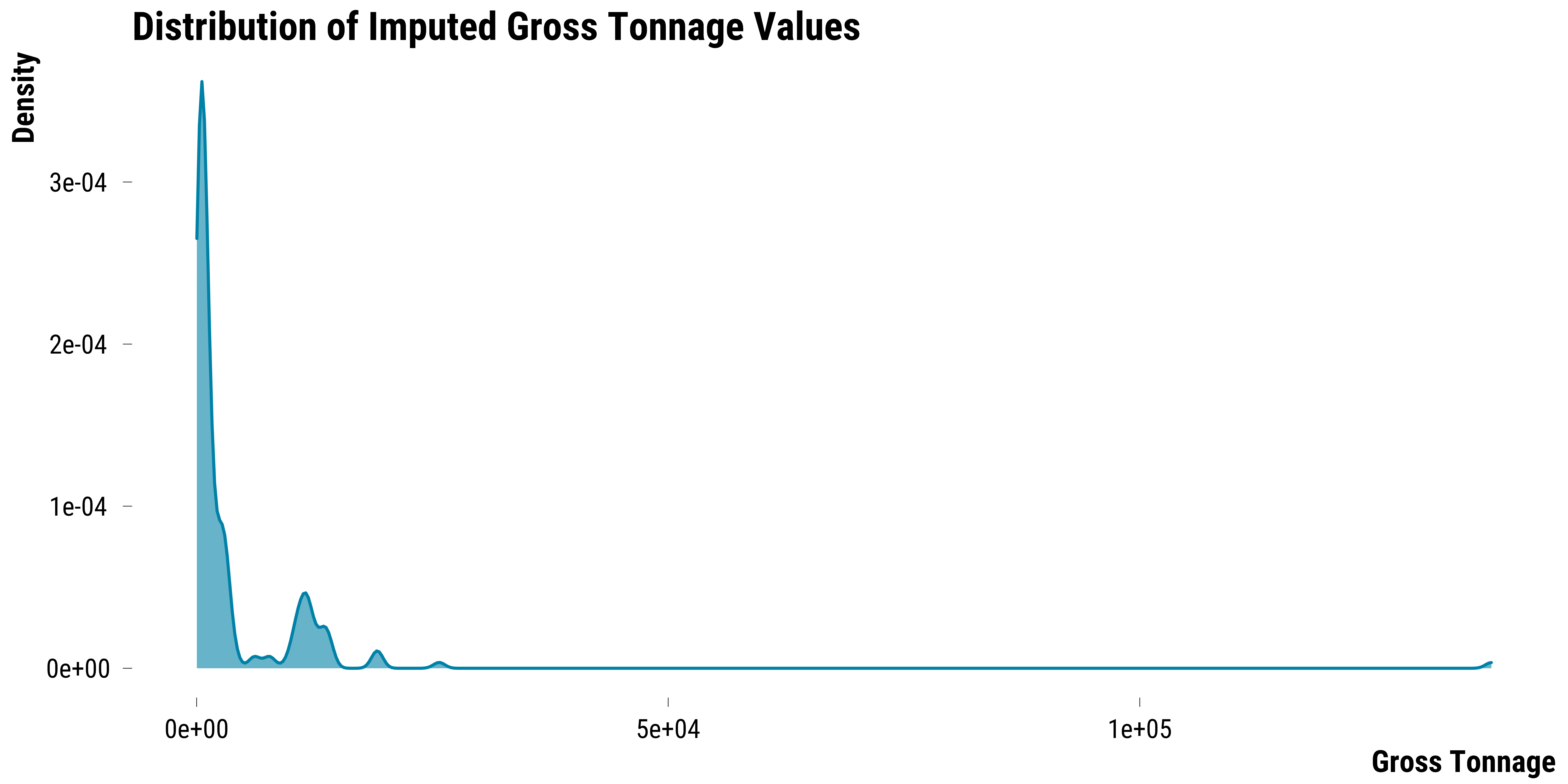
iter 5: ..We plot below the density distribution of the imputed values:
Please show me the code!
port_data %>%
filter(id %in% ids_na) %>%
ggplot(., aes(x = gross_tonnage)) +
geom_density(colour = my_blue,
fill = my_blue,
alpha = 0.6) +
ggtitle("Distribution of Imputed Gross Tonnage Values") +
ylab("Density") +
xlab("Gross Tonnage") +
theme_tufte()
And the table for those observations:
Please show me the code!
# print table of imputed observations
rmarkdown::paged_table(port_data %>%
filter(id %in% ids_na))
The gross tonnage summary statistics for imputed missing values are the following ones:
Please show me the code!
port_data %>%
# filter imputed observations
filter(id %in% ids_na) %>%
# select gross tonnage
select(gross_tonnage) %>%
# compute summary statistics
summarise(
"Mean" = round(mean(gross_tonnage, na.rm = TRUE), 1),
"Standard Deviation" = round(sd(gross_tonnage, na.rm = TRUE), 1),
"Minimum" = round(min(gross_tonnage, na.rm = TRUE), 1),
"Maximum" = round(max(gross_tonnage, na.rm = TRUE), 1)
) %>%
# print table
kable(., align = c(rep("c", 4))) %>%
kable_styling(position = "center")
| Mean | Standard Deviation | Minimum | Maximum |
|---|---|---|---|
| 4046.3 | 11067.6 | 24 | 137276 |
Types of vesselss
Besides gross tonnage, we are also interested in the type of vessels coming to Marseille because:
the time profile of vessel traffic varies depending on the type of vessels. In particular, it could vary depending on whether the vessel is a cruise or a ferry vessel.
the division of maritime traffic by vessel type is also important for the analysis of heterogenous treatment effects.
Below we provide the codes used to define the three main categories of vessels docking in Marseille:
- Cruise vessels
- Ferry vessels
- Other types of vessels
#
# we create three dummies for ferry, cruise and other vessel types
#
# we re-classify some roro vessels which are actually ferry
port_data <- port_data %>%
mutate(roro_correction_dummy = ifelse(
vessel_category == "NAVIRE RO-RO" &
(
holder_name == "KALLISTE" | holder_name == "JEAN NICOLI" |
holder_name == "GIROLATA" |
holder_name == "MONTE D'ORO" |
holder_name == "PAGLIA ORBA" |
holder_name == "PASCAL PAOLI" |
holder_name == "PIANA" |
holder_name == "DENIA CIUTAT CREATIVA"
),
1,
0
))
# dummy for passenger ferry vessels: roros that are actually ferry vessels, car-ferries, "Ro pax" and "vedettes passagers"
port_data <- port_data %>%
mutate(
ferry_vessel = ifelse(
roro_correction_dummy == 1
| vessel_category == "CAR-FERRIE"
| vessel_category == "ROPAX",
1,
0
)
)
# dummy for passenger cruise vessels: vessel_category values equal to "PAQUEBOT" PAQUEBOT FLUVIAL" PLAISANCE" "NAV. DE PLAISANCE"
port_data <- port_data %>%
mutate(cruise_vessel = ifelse(vessel_category == "PAQUEBOT", 1, 0))
# dummy for other vessels: all the vessels that are not ferry nor cruise vessels
port_data <- port_data %>%
mutate(other_vessels = ifelse(ferry_vessel == 0 &
cruise_vessel == 0, 1, 0))
# finally generate gross tonnage variables for each category
port_data <- port_data %>%
mutate(
gross_tonnage_ferry = ferry_vessel * gross_tonnage,
gross_tonnage_cruise = cruise_vessel * gross_tonnage,
gross_tonnage_other_vessels = other_vessels * gross_tonnage
)
We have now defined the three types of vessels. Below are the proportions of vessels belonging to each type:
- 45.4% of vessels are ferries
- 11.7% of vessels are cruise vessels
- 42.9% of vessels are of other types
Final cleaning steps
As final steps, we need to compute the following figures for the total hourly volume of maritime traffic:
- the hourly total gross tonnage entering the port which is the sum of vessels’ gross tonnage when they enter the port
- the hourly total gross tonnage exiting the port which is the sum of vessels’ gross tonnage when they leave the port
- the hourly total gross tonnage which is the sum of the two previous figures
We first transform the entry and exist date variables to keep only the year, the month, day and hour:
port_data <- port_data %>%
mutate(
# transform entry date
entry_date = lubridate::dmy_hm(entry_date) %>% lubridate::round_date(., unit = "hour"),
# transform exit date
exit_date = lubridate::dmy_hm(exit_date) %>% lubridate::ymd_hms(.) %>% lubridate::round_date(., unit = "hour")
)
We check that the date variables are correctly coded:
# entry date
summary(port_data$entry_date)
Min. 1st Qu. Median
"2008-01-01 06:00:00" "2010-07-21 07:00:00" "2013-05-02 07:00:00"
Mean 3rd Qu. Max.
"2013-05-16 19:01:39" "2016-03-11 10:30:00" "2018-12-31 17:00:00" # exit date
summary(port_data$exit_date)
Min. 1st Qu. Median
"2000-01-01 00:00:00" "2010-07-23 14:00:00" "2013-05-03 22:00:00"
Mean 3rd Qu. Max.
"2013-05-18 17:07:51" "2016-03-15 20:30:00" "2019-09-12 15:00:00" Overall, the dates seem to be correctly recorded. 43 exit dates belong to the 2019 year which is strange but we will not use them as we restrict our analysis to the 2008-2018 period.
We then compute for each date variable figures on the daily total sum of the gross tonnage variable and the number of vessels docking/leaving:
# create figures for the entry date
port_data_entry <- port_data %>%
# compute the following statistics by entry date
group_by(entry_date) %>%
summarise(
n_vessels_entry = n(),
n_vessels_entry_ferry = sum(ferry_vessel),
n_vessels_entry_cruise = sum(cruise_vessel),
n_vessels_entry_other_vessels = sum(other_vessels),
total_gross_tonnage_entry_ferry = sum(gross_tonnage_ferry),
total_gross_tonnage_entry_cruise = sum(gross_tonnage_cruise),
total_gross_tonnage_entry_other_vessels = sum(gross_tonnage_other_vessels),
total_gross_tonnage_entry = sum(gross_tonnage)
) %>%
rename(date = entry_date)
# create figures for the exit date
port_data_exit <- port_data %>%
# compute the following statistics by entry date
group_by(exit_date) %>%
summarise(
n_vessels_exit = n(),
n_vessels_exit_ferry = sum(ferry_vessel),
n_vessels_exit_cruise = sum(cruise_vessel),
n_vessels_exit_other_vessels = sum(other_vessels),
total_gross_tonnage_exit_ferry = sum(gross_tonnage_ferry),
total_gross_tonnage_exit_cruise = sum(gross_tonnage_cruise),
total_gross_tonnage_exit_other_vessels = sum(gross_tonnage_other_vessels),
total_gross_tonnage_exit = sum(gross_tonnage)
) %>%
rename(date = exit_date)
we merge the port_data_entry with the
port_data_exit:
# first we create a data column with hours running from 2008 to 2018
# it helps impute with zero values hours where there were no vessels
date_column <-
seq(ymd_hm("2008-01-01 01:00"), ymd_hm("2018-12-31 23:00"), by = "hour") %>%
tibble::enframe(name = NULL, value = "date")
# merge the two datasets
final_port_data <-
left_join(date_column, port_data_entry, by = "date") %>%
left_join(., port_data_exit, by = "date")
And we compute the sum of the number of vessels and the gross tonnage to get the total hourly values:
# compute the sum of figures at the hourly level
final_port_data <- final_port_data %>%
rowwise() %>%
mutate(
n_vessels = sum(n_vessels_entry, n_vessels_exit, na.rm = TRUE),
n_vessels_ferry = sum(n_vessels_entry_ferry, n_vessels_exit_ferry, na.rm =
TRUE),
n_vessels_other_vessels = sum(
n_vessels_entry_other_vessels,
n_vessels_exit_other_vessels,
na.rm = TRUE
),
n_vessels_cruise = sum(n_vessels_entry_cruise, n_vessels_exit_cruise, na.rm =
TRUE),
total_gross_tonnage = sum(total_gross_tonnage_entry, total_gross_tonnage_exit, na.rm =
TRUE),
total_gross_tonnage_ferry = sum(
total_gross_tonnage_entry_ferry,
total_gross_tonnage_exit_ferry,
na.rm = TRUE
),
total_gross_tonnage_other_vessels = sum(
total_gross_tonnage_entry_other_vessels,
total_gross_tonnage_exit_other_vessels,
na.rm = TRUE
),
total_gross_tonnage_cruise = sum(
total_gross_tonnage_entry_cruise,
total_gross_tonnage_exit_cruise,
na.rm = TRUE
)
) %>%
ungroup()
# reorder variables
final_port_data <- final_port_data %>%
select(
date,
n_vessels,
total_gross_tonnage,
n_vessels_cruise,
n_vessels_ferry,
n_vessels_other_vessels,
total_gross_tonnage_cruise,
total_gross_tonnage_ferry,
total_gross_tonnage_other_vessels,
n_vessels_entry,
n_vessels_entry_cruise,
n_vessels_entry_ferry,
n_vessels_entry_other_vessels,
n_vessels_exit,
n_vessels_exit_cruise,
n_vessels_exit_ferry,
n_vessels_exit_other_vessels,
total_gross_tonnage_entry,
total_gross_tonnage_entry_cruise,
total_gross_tonnage_entry_ferry,
total_gross_tonnage_entry_other_vessels,
total_gross_tonnage_exit,
total_gross_tonnage_exit_cruise,
total_gross_tonnage_exit_ferry,
total_gross_tonnage_exit_other_vessels
)
# filter relevant date
final_port_data <- final_port_data %>%
filter(date <= "2018-12-31 23:00:00")
# replace missing values of variables by 0 since it means
# there were not vessels corresponding to the computed statsitics
final_port_data <- final_port_data %>%
mutate_at(vars(n_vessels:total_gross_tonnage_exit_other_vessels),
~ ifelse(is.na(.), 0, .))
Below are the newly created data with the hourly date, the total gross tonnage, the total number of vessels which docked and left the port:
Please show me the code!
# print data
rmarkdown::paged_table(final_port_data)
The summary statistics are the following ones:
Please show me the code!
final_port_data %>%
# drop date variable
select(-date) %>%
# transform data in long format
pivot_longer(cols= c(n_vessels:total_gross_tonnage_exit_other_vessels), names_to = "Variable", values_to = "value") %>%
# compute summary statistics for each variable
group_by(Variable) %>%
summarise("Mean" = round(mean(value, na.rm = TRUE),1),
"Standard Deviation" = round(sd(value, na.rm = TRUE),1),
"Minimum" = round(min(value, na.rm = TRUE),1),
"Maximum" = round(max(value, na.rm = TRUE),1),
"Number of Missing Values" = sum(is.na(value))) %>%
# ungroup data
ungroup() %>%
# arrange variable
arrange(Variable) %>%
# print table
kable(., align = c("l", rep("c", 5))) %>%
kable_styling(position = "center")
| Variable | Mean | Standard Deviation | Minimum | Maximum | Number of Missing Values |
|---|---|---|---|---|---|
| n_vessels | 0.9 | 1.2 | 0 | 12 | 0 |
| n_vessels_cruise | 0.1 | 0.4 | 0 | 10 | 0 |
| n_vessels_entry | 0.4 | 0.9 | 0 | 9 | 0 |
| n_vessels_entry_cruise | 0.0 | 0.3 | 0 | 4 | 0 |
| n_vessels_entry_ferry | 0.2 | 0.6 | 0 | 6 | 0 |
| n_vessels_entry_other_vessels | 0.2 | 0.4 | 0 | 5 | 0 |
| n_vessels_exit | 0.4 | 0.9 | 0 | 8 | 0 |
| n_vessels_exit_cruise | 0.0 | 0.3 | 0 | 7 | 0 |
| n_vessels_exit_ferry | 0.2 | 0.6 | 0 | 6 | 0 |
| n_vessels_exit_other_vessels | 0.2 | 0.5 | 0 | 6 | 0 |
| n_vessels_ferry | 0.4 | 0.8 | 0 | 6 | 0 |
| n_vessels_other_vessels | 0.4 | 0.6 | 0 | 6 | 0 |
| total_gross_tonnage | 24214.2 | 45792.6 | 0 | 507129 | 0 |
| total_gross_tonnage_cruise | 7890.6 | 32447.8 | 0 | 497164 | 0 |
| total_gross_tonnage_entry | 12110.3 | 34347.5 | 0 | 507129 | 0 |
| total_gross_tonnage_entry_cruise | 3945.7 | 23143.1 | 0 | 447470 | 0 |
| total_gross_tonnage_entry_ferry | 5821.2 | 17961.4 | 0 | 204944 | 0 |
| total_gross_tonnage_entry_other_vessels | 2343.5 | 7389.3 | 0 | 175368 | 0 |
| total_gross_tonnage_exit | 12103.9 | 33153.1 | 0 | 497164 | 0 |
| total_gross_tonnage_exit_cruise | 3944.9 | 23375.7 | 0 | 497164 | 0 |
| total_gross_tonnage_exit_ferry | 5819.8 | 17726.7 | 0 | 209914 | 0 |
| total_gross_tonnage_exit_other_vessels | 2339.2 | 7600.9 | 0 | 289078 | 0 |
| total_gross_tonnage_ferry | 11640.9 | 24441.4 | 0 | 227163 | 0 |
| total_gross_tonnage_other_vessels | 4682.7 | 10480.0 | 0 | 289078 | 0 |
Air Pollution Data
Pollution data come from AtmoSud, the local air quality agency accredited by the French Ministry of the Environment. Marseille has only two stations monitoring background air pollution : Saint-Louis and Lonchamp stations. Saint-Louis Station
Saint Louis station is located 2 to 6 kilometers East or South-East from the port depending on the terminal and monitors nitrogen dioxide (NO2), sulphur dioxide (SO2), and Partiulate Matter with a diameter below 2.5 micrometers (PM2.5) and with a diameter between 2.5 and 10 micrometers (PM10). Longchamp station is located 3 to 6 kilometers West or North-West from the port depending on the terminal and monitors NO2, ozone (O3) and PM10.
We gathered hourly data from these background monitoring stations for each pollutant. We received one dataset for all pollutants measures from 2008 to 2011 and one dataset by pollutant from 2012: we therefore have to merge them. Below is the code to clean the data. We also investigate the presence and distribution of missing values.
- We first clean the 2008-2011 data:
# open 2008-2011 data
pollutants_data_2008_2011 <-
data.table::fread(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"1.raw_data",
"2.pollution_data",
"marseille",
"raw_marseille_pollutants_2008_2011_data.csv"
),
check.names = TRUE
) %>%
# rename variables
rename(
date = "Dates",
mean_no2_l = "NO2.CINQAV.microg.m3",
mean_o3_l = "O3.CINQAV.microg.m3",
mean_pm25_l = "PM2.5.CINQAV.microg.m3",
mean_pm10_l = "PM10.CINQAV.microg.m3",
mean_so2_l = "SO2.CINQAV.microg.m3",
mean_no2_sl = "NO2.STLOUI.microg.m3",
mean_pm10_sl = "PM10.STLOUI.microg.m3"
) %>%
# create date variable: some values are missing in the original date column
mutate(date = seq(
as.POSIXct("2008-01-01 01:00:00", tz = "UTC"),
as.POSIXct("2012-01-01 00:00:00", tz = "UTC"),
by = "hour"
)) %>%
# add the row for the missing 2008-01-01 00:00:00 date
add_row(date = as.POSIXct("2008-01-01 01:00:00"), .before = 1) %>%
# transform to ymd_hms format
mutate(date = ymd_hms(date))
The 2008-2011 data are now clean. We then clean each 2012-2018 pollutant file.
- We clean NO2 data with the following code:
# load raw 2012-2018 no2 data
data_no2_2012_2018 <-
data.table::fread(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"1.raw_data",
"2.pollution_data",
"marseille",
"raw_marseille_no2_hourly_2012_2018_data.csv"
),
colClasses = c(rep("character", 96437)),
check.names = TRUE
)
# clean these data
data_no2_2012_2018 <- data_no2_2012_2018 %>%
# transform from wide to long
pivot_longer(
.,
cols = c(`X01.01.2008.0.00`:`X31.12.2018.23.00`),
names_to = "date",
values_to = "mean_no2"
) %>%
# select name of the station, date and mean_no2 variables
select(Station, date, mean_no2) %>%
# transform back from long to wide
pivot_wider(names_from = `Station`, values_from = mean_no2) %>%
# rename the concentration for each station
rename(mean_no2_sl = "Marseille Saint Louis", mean_no2_l = "Marseille-Longchamp") %>%
# transform the concentrations to numeric
mutate_at(vars(mean_no2_sl:mean_no2_l), ~ as.numeric(.)) %>%
# create date variable
mutate(date = seq(
as.POSIXct("2008-01-01 00:00:00", tz = "UTC"),
as.POSIXct("2018-12-31 23:00:00", tz = "UTC"),
by = "hour"
)) %>%
mutate(date = ymd_hms(date)) %>%
# sort by date
arrange(date) %>%
# filter relevant dates
filter(date > "2012-01-01 01:00:00")
- We clean PM10 data with the following code:
# load raw 2012-2018 pm10 data
data_pm10_2012_2018 <-
data.table::fread(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"1.raw_data",
"2.pollution_data",
"marseille",
"raw_marseille_pm10_hourly_2012_2018_data.csv"
),
colClasses = c(rep("character", 96437)),
check.names = TRUE
)
data_pm10_2012_2018 <- data_pm10_2012_2018 %>%
# transform from wide to long
pivot_longer(
cols = c(`X01.01.2008.0.00`:`X31.12.2018.23.00`),
names_to = "date",
values_to = "mean_pm10"
) %>%
# select name of the station, date and mean_pm10 variables
select(Station, date, mean_pm10) %>%
# transform back from long to wide
pivot_wider(names_from = Station, values_from = mean_pm10) %>%
# rename the concentration for each station
rename(mean_pm10_sl = "Marseille Saint Louis", mean_pm10_l = "Marseille-Longchamp") %>%
# transform the concentrations to numeric
mutate_at(vars(mean_pm10_sl:mean_pm10_l), ~ as.numeric(.)) %>%
# create date variable
mutate(date = seq(
as.POSIXct("2008-01-01 00:00:00", tz = "UTC"),
as.POSIXct("2018-12-31 23:00:00", tz = "UTC"),
by = "hour"
)) %>%
mutate(date = ymd_hms(date)) %>%
# sort by date
arrange(date) %>%
# filter relevant dates
filter(date > "2012-01-01 01:00:00")
- We clean PM25 data with the following code:
# load raw pm25 2012-2018 data
data_pm25_2012_2018 <-
data.table::fread(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"1.raw_data",
"2.pollution_data",
"marseille",
"raw_marseille_pm25_hourly_2012_2018_data.csv"
),
colClasses = c(rep("character", 96437)),
check.names = TRUE
)
data_pm25_2012_2018 <- data_pm25_2012_2018 %>%
# transform from wide to long
pivot_longer(
cols = c(`X01.01.2008.0.00`:`X31.12.2018.23.00`),
names_to = "date",
values_to = "mean_pm25"
) %>%
# select name of the station, date and mean_pm25 variables
select(Station, date, mean_pm25) %>%
# transform back from long to wide
pivot_wider(names_from = Station, values_from = mean_pm25) %>%
# rename the concentration for each station
rename(mean_pm25_l = "Marseille-Longchamp") %>%
# transform the concentrations to numeric
mutate_at(vars(mean_pm25_l), ~ as.numeric(.)) %>%
# create date variable
mutate(date = seq(
as.POSIXct("2008-01-01 00:00:00", tz = "UTC"),
as.POSIXct("2018-12-31 23:00:00", tz = "UTC"),
by = "hour"
)) %>%
mutate(date = ymd_hms(date)) %>%
# sort by date
arrange(date) %>%
# filter relevant dates
filter(date > "2012-01-01 01:00:00")
- We clean SO2 data with the following code:
# load raw so2 2012-2018 data
data_so2_2012_2018 <-
data.table::fread(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"1.raw_data",
"2.pollution_data",
"marseille",
"raw_marseille_so2_hourly_2012_2018_data.csv"
),
colClasses = c(rep("character", 96437)),
check.names = TRUE
)
data_so2_2012_2018 <- data_so2_2012_2018 %>%
# transform from wide to long
pivot_longer(
cols = c(`X01.01.2008.0.00`:`X31.12.2018.23.00`),
names_to = "date",
values_to = "mean_so2"
) %>%
# select name of the station, date and mean_so2 variables
select(Station, date, mean_so2) %>%
# transform back from long to wide
pivot_wider(names_from = Station, values_from = mean_so2) %>%
# rename the concentration for each station
rename(mean_so2_l = "Marseille-Longchamp") %>%
# transform the concentrations to numeric
mutate_at(vars(mean_so2_l), ~ as.numeric(.)) %>%
# create date variable
mutate(date = seq(
as.POSIXct("2008-01-01 00:00:00", tz = "UTC"),
as.POSIXct("2018-12-31 23:00:00", tz = "UTC"),
by = "hour"
)) %>%
mutate(date = ymd_hms(date)) %>%
# sort by date
arrange(date) %>%
# filter relevant dates
filter(date > "2012-01-01 01:00:00")
- We clean o3 data with the following code:
# load raw o3 2012-2018 data
data_o3_2012_2018 <-
data.table::fread(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"1.raw_data",
"2.pollution_data",
"marseille",
"raw_marseille_o3_hourly_2012_2018_data.csv"
),
colClasses = c(rep("character", 96437)),
check.names = TRUE
)
data_o3_2012_2018 <- data_o3_2012_2018 %>%
# transform from wide to long
pivot_longer(
cols = c(`X01.01.2008.0.00`:`X31.12.2018.23.00`),
names_to = "date",
values_to = "mean_o3"
) %>%
# select name of the station, date and mean_o3 variables
select(Station, date, mean_o3) %>%
# transform back from long to wide
pivot_wider(names_from = Station, values_from = mean_o3) %>%
# rename the concentration for each station
rename(mean_o3_l = "Marseille-Longchamp") %>%
# transform the concentrations to numeric
mutate_at(vars(mean_o3_l), ~ as.numeric(.)) %>%
# create date variable
mutate(date = seq(
as.POSIXct("2008-01-01 00:00:00", tz = "UTC"),
as.POSIXct("2018-12-31 23:00:00", tz = "UTC"),
by = "hour"
)) %>%
mutate(date = ymd_hms(date)) %>%
# sort by date
arrange(date) %>%
# filter relevant dates
filter(date > "2012-01-01 01:00:00")
Finally, we merge the pollutants 2012-2018 data together and merge this dataframe with the 2008-2011 data:
# merging all pollutants files together
pollutants_data_2012_2018 <- data_no2_2012_2018 %>%
full_join(data_pm10_2012_2018, by = "date") %>%
full_join(data_pm25_2012_2018, by = "date") %>%
full_join(data_so2_2012_2018, by = "date") %>%
full_join(data_o3_2012_2018, by = "date")
# bind 2008-2011 data with 2012-2018 data
pollutants_data <-
bind_rows(pollutants_data_2008_2011, pollutants_data_2012_2018)
Now that the pollutants are gathered, we can look at the summary statistics:
Please show me the code!
pollutants_data %>%
# drop date variable
select(-date) %>%
# transform data in long format
pivot_longer(
cols = c(mean_no2_l:mean_pm10_sl),
names_to = "Variable",
values_to = "value"
) %>%
# compute statistics for each variable
group_by(Variable) %>%
summarise(
"Mean" = round(mean(value, na.rm = TRUE), 1),
"Standard Deviation" = round(sd(value, na.rm = TRUE), 1),
"Minimum" = round(min(value, na.rm = TRUE), 1),
"Maximum" = round(max(value, na.rm = TRUE), 1),
"Proportion of Missing Values" = round(sum(is.na(value)) / n() *
100, 1)
) %>%
# ungroup data
ungroup() %>%
# sort variable
arrange(Variable) %>%
# print table
kable(., align = c("l", rep("c", 5))) %>%
kable_styling(position = "center")
| Variable | Mean | Standard Deviation | Minimum | Maximum | Proportion of Missing Values |
|---|---|---|---|---|---|
| mean_no2_l | 30.0 | 20.0 | 0 | 167 | 2.7 |
| mean_no2_sl | 36.6 | 24.0 | 0 | 251 | 4.8 |
| mean_o3_l | 53.8 | 31.3 | 0 | 234 | 4.5 |
| mean_pm10_l | 26.9 | 15.1 | 0 | 413 | 6.0 |
| mean_pm10_sl | 30.6 | 21.7 | 0 | 577 | 9.0 |
| mean_pm25_l | 15.4 | 10.7 | 0 | 303 | 10.2 |
| mean_so2_l | 2.3 | 4.0 | 0 | 125 | 6.5 |
From this table, you can see that each pollutant has missing values. If you take a look at the patterns of missing values, you will notice that they often happen on consecutive days: a measuring station breaks down and stops recording concentrations. We will impute these values using for each pollutant non-missing values for other stations and pollutants but also from weather and calendar variables.
We save the pollutants_data, which are not imputed,
because we will use them to see how our analysis on the matched data
differs between imputed and non-imputed pollutant concentrations:
Below is the dataframe of pollution variables:
Please show me the code!
rmarkdown::paged_table(pollutants_data)
The pollutants data are now prepared to be matched with the other datasets.
Weather Data
We obtained daiy weather data from Meteo-France, the French national meteorological service. We used data from Marseille airport’s weather station, the closest weather station located 25 kilometers away. We extracted observations on rainfall duration (min), rainfall height (mm), average temperature (°C) and humidity (%), wind speed (m/s) and the direction from which the wind blows (measured on a 360 degrees compass rose where 0° is the true North):
# read the data and rename the variables
weather_data <-
data.table::fread(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"1.raw_data",
"3.weather_data",
"hourly_weather_data.txt"
),
dec = ","
) %>%
rename(
"date" = "DATE",
"rainfall_height" = "RR1",
"rainfall_duration" = "DRR1",
"temperature_average" = "T",
"humidity_average" = "U",
"wind_speed" = "FF",
"wind_direction" = "DD"
) %>%
select(-POSTE)
# convert date variable in date format
weather_data <- weather_data %>%
mutate(date = lubridate::ymd_h(weather_data$date))
Below is the dataframe of the weather variables:
Please show me the code!
rmarkdown::paged_table(weather_data)
And the summary statistics for continuous variables are:
Please show me the code!
weather_data %>%
select(rainfall_height:wind_speed, humidity_average) %>%
gather(key = Variable, value = value) %>%
group_by(Variable) %>%
summarise(
"Mean" = round(mean(value, na.rm = TRUE), 1),
"Standard Deviation" = round(sd(value, na.rm = TRUE), 1),
"Minimum" = round(min(value, na.rm = TRUE), 1),
"Maximum" = round(max(value, na.rm = TRUE), 1),
"Number of Missing Values" = sum(is.na(value))
) %>%
ungroup() %>%
mutate(
Variable = fct_relevel(
Variable,
"rainfall_height",
"rainfall_duration",
"temperature_average",
"humidity_average",
"wind_speed"
)
) %>%
arrange(Variable) %>%
mutate(
Variable = recode(
Variable,
rainfall_height = "Rainfall Height (cm)",
rainfall_duration = "Rainfall Duration (min)",
temperature_average = "Average Temperature (°C)",
humidity_average = "Average Humidity (%)",
wind_speed = "Wind Speed (m/s)"
)
) %>%
kable(., align = c("l", rep("c", 5))) %>%
kable_styling(position = "center")
| Variable | Mean | Standard Deviation | Minimum | Maximum | Number of Missing Values |
|---|---|---|---|---|---|
| Rainfall Height (cm) | 0.1 | 0.7 | 0.0 | 54.4 | 7 |
| Rainfall Duration (min) | 2.6 | 11.3 | 0.0 | 60.0 | 299 |
| Average Temperature (°C) | 15.9 | 7.7 | -9.4 | 38.9 | 0 |
| Average Humidity (%) | 65.2 | 17.4 | 13.0 | 100.0 | 17 |
| Wind Speed (m/s) | 4.7 | 3.6 | 0.0 | 24.9 | 0 |
We can see from these tables that we have very few missing variables.
They will be imputed in the last section with the random forest
algorithm of the missRanger package.
The weather data are now ready to be merged with the other datasets.
Road traffic data (2011-2016 period)
We import road traffic data at the hourly level for the 2011-2016 period. We have the daily flow of vehicles entering and exiting the city averaged over 3 stations:
Below are the summary statistics for the daily flow of vehicles:
Please show me the code!
road_traffic_data %>%
summarise(
"Mean" = round(mean(road_traffic_flow, na.rm = TRUE), 0),
"Standard Deviation" = round(sd(road_traffic_flow, na.rm = TRUE), 0),
"Minimum" = round(min(road_traffic_flow, na.rm = TRUE), 0),
"Maximum" = round(max(road_traffic_flow, na.rm = TRUE), 0),
"Number of Missing Values" = sum(is.na(road_traffic_flow))
) %>%
kable(., align = c("l", rep("c", 5))) %>%
kable_styling(position = "center")
| Mean | Standard Deviation | Minimum | Maximum | Number of Missing Values |
|---|---|---|---|---|
| 2152 | 1411 | 0 | 13408 | 986 |
Calendar Indicators, Bank Days and Holidays Data
First, we create a dataframe with the date variable, the year, the season, the month, the weekend dummy and the day of the week:
# create the date variable
dates_data <-
tibble(date_ymd = seq.Date(
from = as.Date("2008-01-01"),
to = as.Date("2018-12-31"),
by = "day"
))
# create year, month and day of the week indicators
dates_data <- dates_data %>%
mutate(
year = lubridate::year(date_ymd),
season = lubridate::quarter(date_ymd),
month = lubridate::month(date_ymd, label = TRUE, abbr = FALSE),
weekday = lubridate::wday(date_ymd, label = TRUE, abbr = FALSE)
)
# reorder day of the week levels
dates_data <- dates_data %>%
mutate(weekday = ordered(
weekday,
levels = c(
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday",
"Saturday",
"Sunday"
)
))
# create a dummy for the weekend
dates_data <- dates_data %>%
mutate(weekend = ifelse(weekday == "Saturday" |
weekday == "Sunday", 1, 0))
Then, we load two datasets on holidays and bank days indicators:
# load and clean holidays data
data_holidays <-
read.csv(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"1.raw_data",
"4.bank_days_holidays_data",
"data_holidays.csv"
),
stringsAsFactors = FALSE,
encoding = "UTF-8"
) %>%
select(date, vacances_zone_b, nom_vacances) %>%
rename(
date_ymd = date,
holidays_dummy = vacances_zone_b,
holidays_name = nom_vacances
) %>%
mutate(holidays_dummy = ifelse(holidays_dummy == "True", 1, 0)) %>%
mutate(date_ymd = lubridate::ymd(date_ymd)) %>%
filter(date_ymd >= "2008-01-01" & date_ymd < "2019-01-01")
# load and clean bank day data
data_bank_days <-
read.csv(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"1.raw_data",
"4.bank_days_holidays_data",
"data_bank_days.csv"
),
stringsAsFactors = FALSE,
encoding = "UTF-8"
) %>%
rename(
date_ymd = date,
bank_day_dummy = est_jour_ferie,
name_bank_day = nom_jour_ferie
) %>%
mutate(bank_day_dummy = ifelse(bank_day_dummy == "True", 1, 0)) %>%
mutate(date_ymd = lubridate::ymd(date_ymd)) %>%
filter(date_ymd >= "2008-01-01" & date_ymd < "2019-01-01")
We merge the three datasets together:
# merging the calendar data together
dates_data <-
left_join(dates_data, data_holidays, by = "date_ymd") %>%
left_join(., data_bank_days, by = "date_ymd")
We add day_index variable that will be useful to measure
the distance in terms of days between observations for the matching
procedure:
dates_data <- dates_data %>%
# create the day_index variable
mutate(day_index = seq(from = 1, to = 4018, by = 1))
Below is the dataframe for the calendar indicators:
Please show me the code!
rmarkdown::paged_table(dates_data)
Merging all Data
We finally need to merge all the datasets together:
# we first merge weather_data and pollution data
data <- left_join(weather_data, pollutants_data, by = "date") %>%
# we merge the data with maritime traffic data
left_join(., final_port_data, by = "date") %>%
# we merge the data with road traffic data
left_join(., road_traffic_data, by = "date")
# we then create a new date variable to merge with the dates_data
data <- data %>%
mutate(date_ymd = str_sub(date, start = 1, end = 10) %>% lubridate::ymd(.))
# we finally merge the dates_data with data
data <- left_join(data, dates_data, by = "date_ymd")
We add the hour variable:
data <- data %>%
# create the hour variable
mutate(hour = lubridate::hour(date)) %>%
select(date, hour, everything())
Below is the proportion of missing values by variables:
Please show me the code!
data %>%
mutate_all( ~ as.character(.)) %>%
pivot_longer(cols = everything(),
names_to = "variable",
values_to = "value") %>%
group_by(variable) %>%
summarise("Proportion of Missing Values (%)" = round(sum(is.na(value) /
nrow(data) * 100), 1)) %>%
kable(.) %>%
kable_styling(position = "center")
| variable | Proportion of Missing Values (%) |
|---|---|
| bank_day_dummy | 0.0 |
| date | 0.0 |
| date_ymd | 0.0 |
| day_index | 0.0 |
| holidays_dummy | 0.0 |
| holidays_name | 0.0 |
| hour | 0.0 |
| humidity_average | 0.0 |
| mean_no2_l | 2.7 |
| mean_no2_sl | 4.8 |
| mean_o3_l | 4.5 |
| mean_pm10_l | 6.0 |
| mean_pm10_sl | 9.0 |
| mean_pm25_l | 10.2 |
| mean_so2_l | 6.5 |
| month | 0.0 |
| n_vessels | 0.0 |
| n_vessels_cruise | 0.0 |
| n_vessels_entry | 0.0 |
| n_vessels_entry_cruise | 0.0 |
| n_vessels_entry_ferry | 0.0 |
| n_vessels_entry_other_vessels | 0.0 |
| n_vessels_exit | 0.0 |
| n_vessels_exit_cruise | 0.0 |
| n_vessels_exit_ferry | 0.0 |
| n_vessels_exit_other_vessels | 0.0 |
| n_vessels_ferry | 0.0 |
| n_vessels_other_vessels | 0.0 |
| name_bank_day | 0.0 |
| rainfall_duration | 0.3 |
| rainfall_height | 0.0 |
| road_traffic_flow | 48.5 |
| season | 0.0 |
| temperature_average | 0.0 |
| total_gross_tonnage | 0.0 |
| total_gross_tonnage_cruise | 0.0 |
| total_gross_tonnage_entry | 0.0 |
| total_gross_tonnage_entry_cruise | 0.0 |
| total_gross_tonnage_entry_ferry | 0.0 |
| total_gross_tonnage_entry_other_vessels | 0.0 |
| total_gross_tonnage_exit | 0.0 |
| total_gross_tonnage_exit_cruise | 0.0 |
| total_gross_tonnage_exit_ferry | 0.0 |
| total_gross_tonnage_exit_other_vessels | 0.0 |
| total_gross_tonnage_ferry | 0.0 |
| total_gross_tonnage_other_vessels | 0.0 |
| weekday | 0.0 |
| weekend | 0.0 |
| wind_direction | 0.0 |
| wind_speed | 0.0 |
| year | 0.0 |
Imputing missing values for air pollution and weather variables
We finally impute missing values for air pollution and weather variables.
Simulation Exercise
Before carrying out the imputation procedure, we provide evidence that the missRanger package works well in this framework. Similar to our test in the boat data section, we carry out a simulation to show that imputed values are close to real values. We start by creating the data_test where we drop all rows that contain at least a missing values for a selected subset of variables.
# create data_test
data_test <- data %>%
# drop rows with at least a missing value
drop_na() %>%
# create an index
mutate(id = seq(1:33953))
To mimick measuring stations that break down, we are going to erase values of two pollutants that belong to four weeks selected at random. However, we are are not going to erase values for all variables that belong to these weeks. Concomitant missingness of all variables rarely happens in our data. We choose to erase values for NO2 and PM2.5 pollutants measured at longchamp station. NO2 is also measured at Saint-Louis station so the algorithm might be able to use its records to impute concentrations at Longchamp station. PM2.5 is however only measured at Longchamp station . it might be more difficult for the algorithm to guess the true values. Below is the code to create missing values:
# weeks whose observations should be erased
weeks_selected <- sample(seq(1:52), 4)
# create the week variables
data_test <- data_test %>%
mutate(week = lubridate::week(date))
# create data_test_na where we erase values for selected weeks
data_test_na <- data_test %>%
# select relevant weeks
filter(week %in% weeks_selected) %>%
# erase values for those observations
mutate_at(vars(mean_no2_l, mean_pm25_l), ~ . == NA)
# bind data_test without the missing values with data_test_na
data_test_na <-
bind_rows((data_test %>% filter(!(
week %in% weeks_selected
))), data_test_na)
We impute the missing values using the missRanger
algorithm. 100 trees and pmm.k parameter equal to 10 seem to give
reasonable imputed values:
# running the imputation algorithm
data_test_imputed <- missRanger::missRanger(
data_test_na,
# variables to impute
mean_no2_l + mean_pm25_l ~
# variables used for the imputation
mean_no2_sl + mean_no2_l + mean_pm10_sl + mean_pm10_l + mean_pm25_l + mean_so2_l + mean_o3_l + rainfall_height + rainfall_duration + temperature_average + wind_speed + wind_direction + humidity_average + total_gross_tonnage + road_traffic_flow + hour + weekday + holidays_dummy + bank_day_dummy + month + year,
pmm.k = 10,
num.trees = 100,
seed = 42
)
Missing value imputation by random forests
Variables to impute: mean_no2_l, mean_pm25_l
Variables used to impute: mean_no2_sl, mean_no2_l, mean_pm10_sl, mean_pm10_l, mean_pm25_l, mean_so2_l, mean_o3_l, rainfall_height, rainfall_duration, temperature_average, wind_speed, wind_direction, humidity_average, total_gross_tonnage, road_traffic_flow, hour, weekday, holidays_dummy, bank_day_dummy, month, year
iter 1: ..
iter 2: ..
iter 3: ..We can check that missing NO2 values were correctly imputed:
# true no2 at longchamp station
true_no2_l <- data_test %>%
filter(week %in% weeks_selected) %>%
select(id, mean_no2_l) %>%
rename("True NO2 at longchamp" = mean_no2_l)
# imputed no2 at saint-louis station
imputed_no2_l <- data_test_imputed %>%
filter(week %in% weeks_selected) %>%
select(id, mean_no2_l) %>%
rename("Imputed NO2 at longchamp" = mean_no2_l)
# combining true and imputed no2 values together
no2_comparison_df <-
left_join(true_no2_l, imputed_no2_l, by = "id")
# plotting density distributions
no2_comparison_df %>%
gather(., key = "variable", value = "value",-id) %>%
ggplot(., aes(x = value, colour = variable)) +
geom_density(alpha = 0.2) +
scale_color_manual(
name = "Observations:",
labels = c("True NO2 at longchamp", "Imputed NO2 at longchamp"),
values = c(my_blue, my_orange)
) +
scale_fill_manual(
name = "Observations:",
labels = c("True NO2 at longchamp", "Imputed NO2 at longchamp"),
values = c(my_blue, my_orange)
) +
scale_y_continuous(labels = scales::comma) +
ylab("Density") +
xlab("Hourly Mean NO2 (µg/m³)") +
labs(colour = "Observations:") +
theme_tufte()
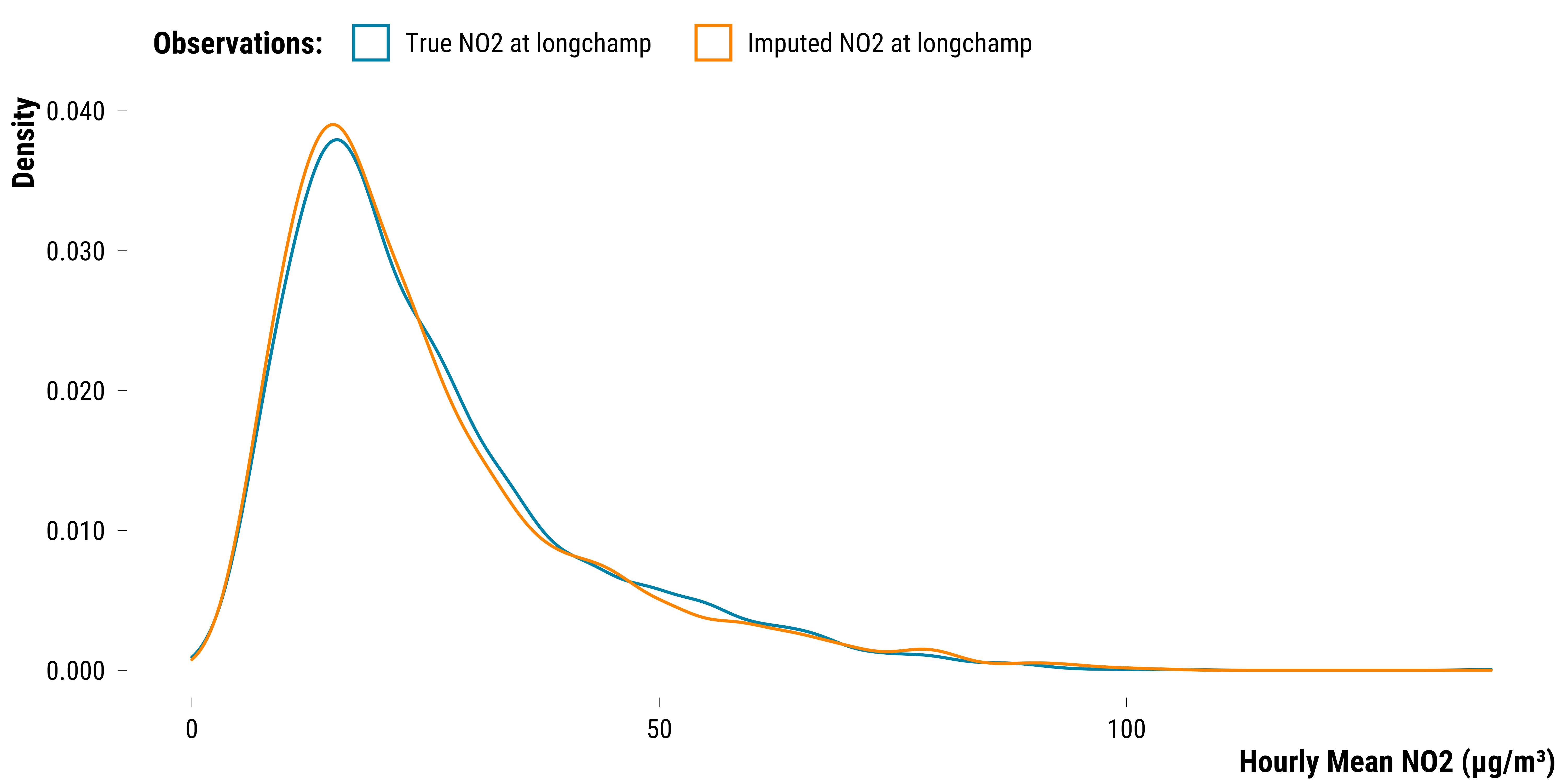
The overlap of the two densities is not perfect but seems decent. We show below the table for the imputed and true values of missing NO2 observations:
# joining the true and imputed values together and computing the difference
no2_comparison_df <-
left_join(true_no2_l, imputed_no2_l, by = "id") %>%
mutate(Difference = abs(`True NO2 at longchamp` - `Imputed NO2 at longchamp`)) %>%
rename("Observation Id" = id)
# print table
rmarkdown::paged_table(no2_comparison_df)
The absolute average difference is 6.5 µg/m³. Given that the hourly NO2 average is 30 µg/m³, it is an important average error. We plot below the distribution of the true PM2.5 concentrations and the ones imputed:
# true pm2.5 at longchamp station
true_pm25_l <- data_test %>%
filter(week %in% weeks_selected) %>%
select(id, mean_pm25_l) %>%
rename("True PM2.5 at longchamp" = mean_pm25_l)
# imputed pm2.5 atat longchamp station
imputed_pm25_l <- data_test_imputed %>%
filter(week %in% weeks_selected) %>%
select(id, mean_pm25_l) %>%
rename("Imputed PM2.5 at longchamp" = mean_pm25_l)
# combining true and imputed pm2.5 values together
pm25_comparison_df <-
left_join(true_pm25_l, imputed_pm25_l, by = "id")
# plotting density distributions
pm25_comparison_df %>%
gather(., key = "variable", value = "value",-id) %>%
ggplot(., aes(x = value, colour = variable)) +
geom_density(alpha = 0.2) +
scale_color_manual(
name = "Observations:",
labels = c("True PM2.5 at longchamp", "Imputed PM2.5 at longchamp"),
values = c(my_blue, my_orange)
) +
scale_fill_manual(
name = "Observations:",
labels = c("True PM2.5 at longchamp", "Imputed PM2.5 at longchamp"),
values = c(my_blue, my_orange)
) +
scale_y_continuous(labels = scales::comma) +
ylab("Density") +
xlab("Hourly Mean PM2.5 ((µg/m³)") +
labs(colour = "Observations:") +
theme_tufte()
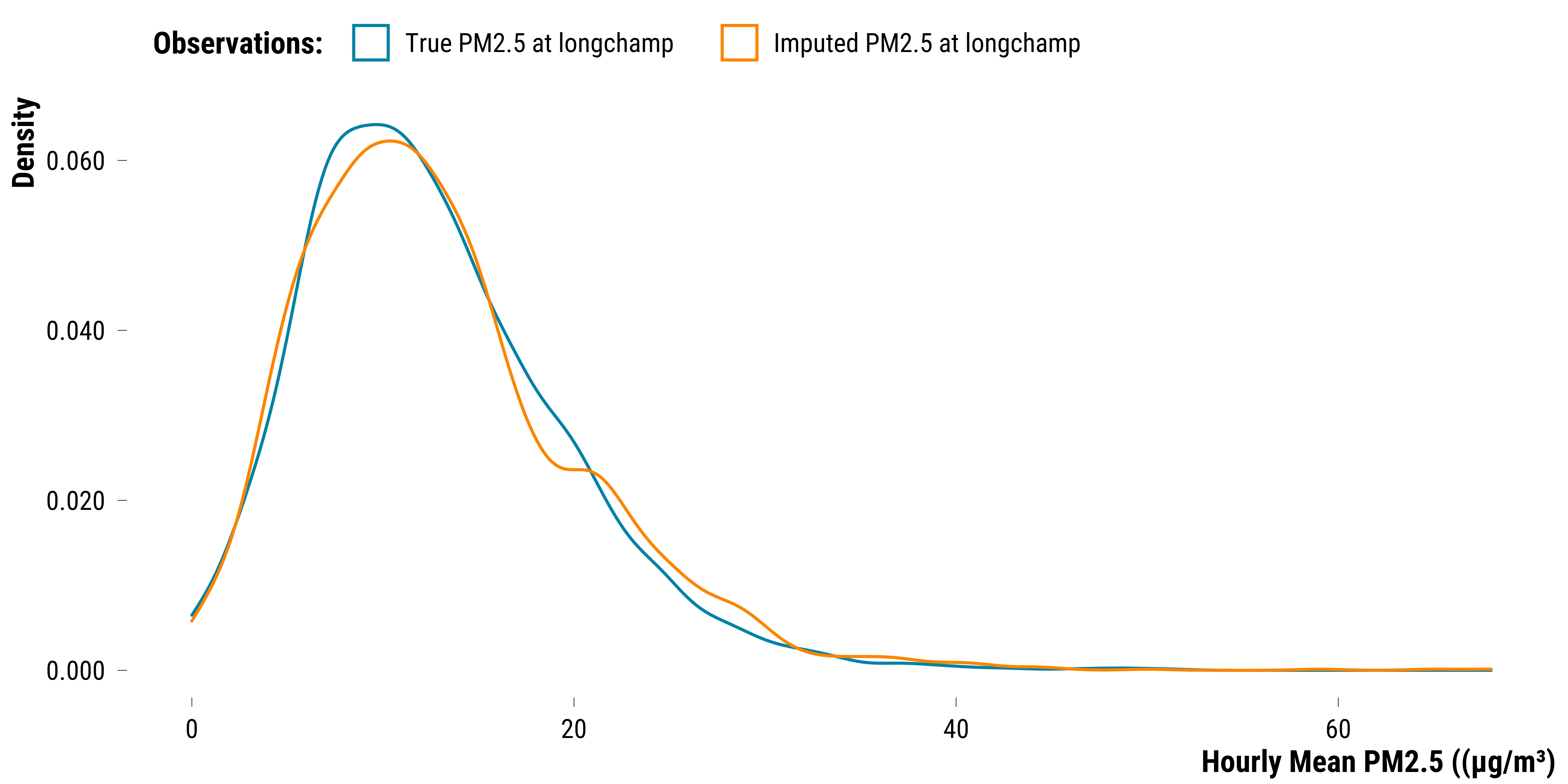
The overlap of the two densities is again not perfect but seems to be decent. We show below the table of the true and imputed values for each observation and the absolute difference:
Please show me the code!
# joining the true and imputed values together and computing the difference
pm25_comparison_df <-
left_join(true_pm25_l, imputed_pm25_l, by = "id") %>%
mutate(Difference = abs(`True PM2.5 at longchamp` - `Imputed PM2.5 at longchamp`)) %>%
rename("Observation Id" = id)
# print table
rmarkdown::paged_table(pm25_comparison_df)
The absolute average difference is 3.4 µg/m³. Given that the daily average of PM2.5 is 15.4 µg/m³, this is again an important imputation error.
It seems therefore that the imputation algorithm has a decent performance in this small simulation exerise but might lead to relatively large imputation errors. Besides, we should keep in mind that if many weather variables were happened to be missing at the same time of a monitoring station’s failure, the algorithm would have troubles correctly predicting its values.
Imputation Procedure
We finally impute the real missing values for the data:
data <- missRanger::missRanger(
data,
# variables to impute
mean_no2_sl + mean_no2_l + mean_pm10_sl + mean_pm10_l + mean_pm25_l + mean_so2_l + mean_o3_l + rainfall_height + rainfall_duration + temperature_average + wind_speed + wind_direction + humidity_average ~
# variables used for the imputation
mean_no2_sl + mean_no2_l + mean_pm10_sl + mean_pm10_l + mean_pm25_l + mean_so2_l + mean_o3_l + rainfall_height + rainfall_duration + temperature_average + wind_speed + wind_direction + humidity_average + total_gross_tonnage + road_traffic_flow + hour + weekday + holidays_dummy + bank_day_dummy + month + year,
pmm.k = 10,
num.trees = 100,
seed = 42
)
saveRDS(
data,
here::here(
"inputs",
"1.data",
"1.hourly_data",
"2.data_for_analysis",
"0.main_data",
"data_for_analysis_hourly_before_imputation.rds"
))
Final Cleaning Steps
Creating Rainfall Dummy and Wind Direction Categories
We create a dummy for the rainfall_height variable to
know if for a given hour it rained:
We can also sort the wind direction into four main directions (North-East, South-East, South-West, North-West):
# create u and v components of the wind vector
data <- data %>%
mutate(
wind_direction_categories = cut(
wind_direction,
breaks = seq(0, 360, by = 90),
include.lowest = TRUE
) %>%
recode(
.,
"[0,90]" = "North-East",
"(90,180]" = "South-East",
"(180,270]" = "South-West",
"(270,360]" = "North-West"
)
)
We also also sort the wind direction into two main directions (East and West) as they are two broad directions that could matter to bring or chase pollution emitted by boats:
Daily Lags of Covariates
We match for each hour, the coviariates for the two previous days. This will allow us to check that two identical hours for a set of covariates are also similar in terms of daily covariates for the two previous days.
# load the daily data
daily_data <-
readRDS(
here::here(
"inputs",
"1.data",
"1.hourly_data",
"2.data_for_analysis",
"0.main_data",
"data_for_analysis_daily.rds"
)
) %>%
select(
date,
mean_no2_sl,
mean_no2_l,
mean_pm10_sl,
mean_pm10_l,
mean_pm25_l,
mean_so2_l,
mean_o3_l,
rainfall_height_dummy,
temperature_average,
wind_speed,
wind_direction_east_west,
wind_direction_categories,
humidity_average,
total_gross_tonnage
)
daily_data <- daily_data %>%
rename_at(vars(-date), function(x)
paste0("daily_", x))
# create a list to store dataframe of lags
lags_list <- vector(mode = "list", length = 2)
names(lags_list) <- c(1:2)
# create the lags
for (i in 1:2) {
lags_list[[i]] <- daily_data %>%
mutate_at(vars(-date), ~ lag(., n = i, order_by = date)) %>%
rename_at(vars(-date), function(x)
paste0(x, "_lag_", i))
}
# merge the dataframes of lags
daily_data_lags <- lags_list %>%
reduce(left_join, by = "date")
# rename date
daily_data_lags <- daily_data_lags %>%
rename(date_daily = date)
# merge with hourly data
data <- data %>%
mutate(date_daily = format(as.Date(date), "%Y-%m-%d")) %>%
mutate(date_daily = lubridate::ymd(date_daily)) %>%
select(date, date_daily, everything())
# merge the data with the daily data lags
data <- left_join(data, daily_data_lags, by = "date_daily")
Saving the Data
We reorder the variables:
# reorder variables
data <- data %>%
select(
# calendar variables
date,
day_index,
hour,
year,
season,
month,
weekday,
weekend,
holidays_dummy,
holidays_name,
bank_day_dummy,
name_bank_day,
# weather variables
temperature_average:wind_direction_east_west,
daily_rainfall_height_dummy_lag_1:daily_humidity_average_lag_1,
daily_rainfall_height_dummy_lag_2:daily_humidity_average_lag_2,
# pollution variables
mean_no2_l:mean_pm10_sl,
daily_mean_no2_sl_lag_1:daily_mean_o3_l_lag_1,
daily_mean_no2_sl_lag_2:daily_mean_o3_l_lag_2,
# maritime traffic variables
n_vessels,
total_gross_tonnage,
n_vessels_cruise,
n_vessels_ferry,
n_vessels_other_vessels,
total_gross_tonnage_cruise,
total_gross_tonnage_ferry,
total_gross_tonnage_other_vessels,
n_vessels_entry,
n_vessels_entry_cruise,
n_vessels_entry_ferry,
n_vessels_entry_other_vessels,
n_vessels_exit,
n_vessels_exit_cruise,
n_vessels_exit_ferry,
n_vessels_exit_other_vessels,
total_gross_tonnage_entry,
total_gross_tonnage_entry_cruise,
total_gross_tonnage_entry_ferry,
total_gross_tonnage_entry_other_vessels,
total_gross_tonnage_exit,
total_gross_tonnage_exit_cruise,
total_gross_tonnage_exit_ferry,
total_gross_tonnage_exit_other_vessels,
daily_total_gross_tonnage_lag_1,
daily_total_gross_tonnage_lag_2,
# road traffic variable
road_traffic_flow
)
We save the data in the 1.data/2.data_for_analysis/0.main_data folder: